인터널 테이블( Internal Table)이란?
Table은 물리적인 존재로 DBMS에 의해 실제 데이터가 저장되지만 반면 Internal Table은 프로그램 실행 중에 정의되어 사용되는 로컬 테이블로 임시 성격을 가집니다.
쉽게 말해, 데이터베이스(DBMS)에 저장된 데이터와는 달리 프로그램 내에서만 사용되는 "임시 테이블"입니다
메모리 영역에서 사용되는 테이블은 Internal Table이라고 하며, DBMS에서 사용하는 테이블은 Table 또는 Transparent Table이라고 합니다.
SAP에서는 다양한 데이터를 처리할 때 데이터베이스 테이블에서 데이터를 읽고, 필요한 만큼 메모리 내에서 조작을 해야 할 때 Internal Table을 사용합니다.
구조는 어떻게 되어 있는가?(Structure, WorkArea, Interner Table)
SAP에서 많이 쓰는 변수는 크게 DATA, STRUCTURE, INTERNAL TABLE 크게 3가지로 볼 수 있습니다.
인터널 테이블의 구조를 알기전에 우선 Structure와 Work Area에 대한 이해가 필요합니다.
Structure(구조체)
단순히 테이블의 형식이나 구조를 정의하는 데이터 타입입니다. 각 필드가 어떤 데이터 타입을 가질지 정의하는 것입니다.
정리해보면
구조체는 데이터를 저장하는 용도가 아니며 데이터의 형식(어떤 필드들이 있고, 그 필드들이 어떤 데이터 타입을 가지는지)을 정의하는 것입니다
즉, 구조체는 어떤 데이터가 들어갈지에 대한 "청사진"이라고 할 수 있습니다.
구조체 자체는 레코드를 가질 수 없고, 이를 바탕으로 워크 에어리어나 인터널 테이블 같은 데이터 구조를 만들 수 있습니다.

WorkArea
Work Area는 하나의 레코드를 저장하는 데 사용됩니다. Internal Table과 밀접하게 연관되어 있으며, 주로 Internal Table에 데이터를 추가하거나 수정할 때 사용됩니다. Work Area는 하나의 레코드만 담을 수 있는 데이터 구조입니다.
<주요 특징>
- 하나의 레코드만 담을 수 있음:
- Work Area는 한 번에 하나의 레코드만 가질 수 있습니다. 즉, 여러 개의 데이터를 저장할 수 없습니다.
- 여러 레코드를 저장하고자 할 때는 Internal Table을 사용해야 합니다.
- Internal Table에 데이터를 추가할 때 사용:
- 데이터를 Internal Table에 삽입할 때, 먼저 Work Area에 데이터를 채우고, 이를 Internal Table에 APPEND하거나 INSERT 명령을 사용하여 추가합니다.
- 직접 Internal Table에 데이터를 삽입할 수 없고, 항상 Work Area를 통해 데이터를 삽입해야 합니다.
- 구조체와 동일한 구조:
- Work Area는 Internal Table의 구조와 동일해야 합니다. 즉, Work Area와 Internal Table은 동일한 필드를 가져야만 합니다.
- Work Area는 Internal Table에 데이터를 추가하거나 수정하는 역할을 합니다.
- 메모리 내에서만 존재:
- Work Area는 프로그램 실행 중에만 존재하며, 데이터 딕셔너리에는 저장되지 않습니다.
- 프로그램이 실행되면 메모리에서 동적으로 생성되고, 실행이 종료되면 사라집니다.

Interner Table
인터널 테이블은 기본적으로 행(Row)과 열(Column)로 구성된 2차원 배열 형태입니다. 각 행은 하나의 레코드를 의미하고, 각 열은 필드를 의미합니다. 내부적으로 각 행은 라인(Line) 이라고도 불립니다.
- 행(Row): 테이블의 각 데이터 항목.
- 열(Column): 각 행의 속성. DB 테이블의 필드와 유사합니다.

정리
각 유형을 정리해보면 아래와 같이 정리할 수 있습니다.

인터널 테이블( Internal Table) 종류
인터널 테이블에는 다양한 종류가 있으며, 주요한 세 가지 종류가 있습니다:
- 표준 테이블(Standard Table):
- 기본적인 테이블로, 데이터 삽입 시 순차적으로 데이터를 저장합니다.
- 인덱스를 사용하여 데이터를 접근할 수 있습니다.( Index 또는 Key로 해당 Row를 찾아갈수 있습니다.)
- 순서 무작위, 추가&삽입 자유로움, 검색속도 느림
- 선언 예시
1. STRUCTURE TYPE 선언 TYPES: BEGIN OF t_line, field1 TYPE c LENGTH 5, field2 TYPE c LENGTH 4, END OF t_line. 2. Standard Table 타입 선언 TYPES t_tab TYPE STANDARD TABLE OF t_line WITH NON-UNIQUE DEFAULT KEY. 3. Internal Table 선언 DATA gt_itab TYPE t_tab WITH HEADER LINE.
- 정렬 테이블(Sorted Table):
- 데이터를 삽입할 때 key값으로 항상 자동으로 정렬됩니다.( 즉, 프로그래머가 원하는 Key 값으로 항상 정렬된 결과로 인터널 테이블에 저장해야 하는 경우에 사용합니다.)
- 인덱스를 사용하여 데이터를 접근할 수 있습니다.
- BINARY SEARCH 방식으로 데이터를 빠르게 검색할 수 있습니다.
- 자동정렬, 중복 허용 여부 설정 가능, 검색속도 빠름
- 선언 예시
TYPES t_tab TYPE SORTED TABLE OF t_line WITH UNIQUE KEY field1.
Standard Table과 다르게 Key값을 선언할 때 WITH UNIQUE를 사용할 수 있습니다.
Sorted Table은 내부적으로 BINARY SEARCH를 사용하기 때문에 Sort 명령어를 사용하면 오류가 납니다.
또한 항상 정렬된 상태를 유지하기 때문에 데이터를 추가할 때 INSERT/APPEND 구분을 잘 해야합니다
**선언은 위의 선언에서 Table 타입 선언만 바꾸면됩니다.
- 해시 테이블(Hash Table):
- 고유한 키 값을 이용하여 데이터를 저장합니다.
- 순차적인 Index를 가지고 있지 않으며, Hash 값으로 계산된 Key값으로만 탐색할 수 있습니다
- HASHED 테이블로, 키 값을 통해 빠른 검색이 가능합니다.
- 검색 최적화, 중복 불가, 검색 속도 가장 빠름
TYPES t_tab TYPE HASHED TABLE OF t_line WITH UNIQUE KEY field1.- Hashed Table은 반드시 Unique 하게 선언해야 합니다
정리해보면 아래와같습니다.
| 테이블 종류 | 특징 | 삽입(Append) | 삽입(Insert) | 검색속도 |
| Standard Table | 기본 인터널 테이블(순서 없음) | o | o | 느림(순차 검색) |
| Sorted Table | 자동 정렬됨(Primary Key 기준) | x | o | 빠름(이진 검색) |
| Hash Table | 해시 알고리즘으로 검색 최적화 | x | o | 매우 빠름(해시 검색) |
인터널 테이블( Internal Table) 선언 방법
인터널 테이블을 선언하는 방법은 3가지로 구분됩니다.
1. 테이블 타입(Type) 정의 후 선언
테이블 타입(Table Type)을 TYPES를 사용해 정의한 후, 그 타입을 기반으로 인터널 테이블을 선언하는 방식입니다.
* 1. 워크 에어리어(스트럭처) 정의
TYPES: BEGIN OF ts_struct,
field1 TYPE data_type1,
field2 TYPE data_type2,
field3 TYPE data_type3,
field4 TYPE data_type4,
END OF ts_struct.
* 2. 테이블 타입 정의
TYPES tt_struct TYPE STANDARD TABLE OF ts_struct
WITH NON-UNIQUE KEY field1 field2.
* 3. 테이블 정의
DATA gt_table TYPE tt_struct.
2. 스트럭처 타입을 직접 사용하여 선언하는 방법
테이블 타입을 별도로 정의하지 않고, 바로 스트럭처 타입(Structure Type)을 사용하여 인터널 테이블을 선언하는 방식입니다.
DATA gt_table TYPE STANDARD TABLE OF ts_struct
WITH NON-UNIQUE KEY field1 field2.
3. 기존 Transparent Table을 기반으로 선언하는 방법
DATA gt_table TYPE TABLE OF db_table. " SAP DB 테이블을 그대로 사용
정리해보면 아래와같습니다.
| 방법 | 선언 | 특징 |
| 테이블 타입(Type) 정의 후 선언 | TYPES를 사용해 테이블 타입을 정의 TYPES.... TYPE STANDARD TABLE OF.... 이후 인터널 테이블 선언 DATA....TYPE.... |
재사용 가능, 키 설정 가능, 가독성 좋음 |
| 스트럭쳐 타입을 직접 사용 | 스트럭쳐 타입 사용하여 인터널 테이블 정의 DATA....TPYE STANDARD TABLE OF...[스트럽쳐 타입] |
빠르게 선언 가능, 간단한 테이블에 적합 |
| Transparent Table을 기반으로 선언 | 테이블을 사용하여 인터널 테이블 정의 DATA....TYPE TABLE OF....[테이블[] |
데이터베이스 테이블과 동일한 구조유지 |
인터널 테이블( Internal Table) 의 헤더라인
인터널 테이블 헤더라인이란?
헤더라인은 하나의 Work Area 로 생각하면됩니다.
현재 S4HANA에서는 Work Area 와 인터널 테이블을 다르게 구분하기 위해서 지향한다고 합니다.
그래서 GS_LIST(Work Area) , GT_LIST(인터널테이블) 이런식으로 선언하는게 맞지만
예전에 사용 되는 문법이라 해당 대념을 짚고 넘어갈 필요가 있습니다.
Header Line (헤더라인)은 인터널 테이블(Internal Table)과 Work Area를 보다 간단히 다룰 수 있도록 하기 위해 만들어졌습니다.
원래 인터널 테이블에 데이터를 입력하기 위해서는 Work Area 에 데이터를 넣은 뒤 인터널 테이블에 다시 넣어줘야 합니다. 하지만 헤더를 가지고 있는 인터널 테이블의 경우 헤더가 구조체 역할을 하므로 따로 구조체를 선언할 필요가 없습니다.
Header Line의 주요 목적은 기존 방식의 편의성과 코드 간소화였습니다.
헤더 라인은 인터널 테이블을 선언할 때 자동으로 하나의 레코드(Work Area)를 내장하게 하여 프로그램 내에서 중복 선언을 방지하고, 코드를 간결하게 만들기 위해 만들어졌습니다. 즉, 헤더 라인을 사용하면 별도로 Work Area를 선언하지 않고도 인터널 테이블에 데이터를 삽입할 수 있었기 때문에, 개발자는 코드 작성이 더 간편해졌습니다.
헤더라인이 있는 테이블 vs 헤더라인이 없는 테이블
헤더라인이 있는 테이블과 헤더라인이 없는 테이블의 구조는 아래와같습니다.

이 두 인터널 테이블의 차이점은 내부적으로 스트럭처를 가지고 있느냐 없느냐입니다.
헤더라인이 있는 인터널 테이블은 테이블을 생성함과 동시에 그 테이블의 타입을 참조하여 스트럭처도 하나 생성해주는 효과가 있습니다.
헤더라인이 있는 테이블과 헤더라인이 없는 테이블
LOOP문을 통해 헤더라인이 있는 테이블과 없는 테이블을 비교해 봅시다.
헤더라인이 있는 테이블
헤더라인 이 있는 테이블을 선언해줍니다.
TYPES:
BEGIN OF wa_table,
id TYPE i,
name TYPE string,
END OF wa_table.
DATA: lt_table TYPE TABLE OF wa_table WITH HEADER LINE.work area wa_table을 선언하고 헤더라인이 있는 인터널 테이블 It_table을 선언 하였습니다.
비교에 앞서 헤더라인이 있는 인터널 테이블은 실제로 어떤 구조로 되어있는지 알아 봅시다.

위 처럼 헤더라인이 있는 인터널 테이블을 선언하게되면
테이블 형태의 LT_TABLE와 , Work area 형태의 LT_TABLE[] 이 만들어집니다.
LT_TABLE 은 일반적인 테이블 구조로 아래와같으며

LT_TABLE[]는 하나의 레코드를 가진 형태로 볼수 있습니다.

헤더라인이 있는 LT_TABLE에 LOOP문을 통해 데이터가 어떻게 삽입되는지 하나씩 알아봅시다.
아래는 It_existing_table 테이블에 데이터를 삽입하고 it_table (인터널 테이블)에 데이터를 Loop문을 넣는 코드를 통해
인터널테이블에 데이터를 삽입하는 코드입니다.
TYPES:
BEGIN OF wa_table,
id TYPE i,
name TYPE string,
END OF wa_table.
DATA:
" 기존 데이터가 들어있는 테이블 선언
lt_existing_table TYPE TABLE OF wa_table.
" 기존 데이터 삽입 (예시 데이터)
APPEND VALUE #( id = 1 name = 'John' ) TO lt_existing_table.
APPEND VALUE #( id = 2 name = 'Jane' ) TO lt_existing_table.
APPEND VALUE #( id = 3 name = 'Alice' ) TO lt_existing_table.
APPEND VALUE #( id = 4 name = 'Bob' ) TO lt_existing_table.
" 헤더라인이 있는 인터널 테이블 선언
DATA:
lt_table TYPE TABLE OF wa_table WITH HEADER LINE.
" lt_existing_table의 데이터를 lt_table에 추가 (헤더라인 사용)
LOOP AT lt_existing_table INTO DATA(ls_existing_entry).
lt_table-id = ls_existing_entry-id. " 헤더라인에 값 설정
lt_table-name = ls_existing_entry-name. " 헤더라인에 값 설정
BREAK-POINT.
APPEND lt_table. " 헤더라인을 lt_table에 추가
ENDLOOP.
여기서 우리가 주의 깊에 봐야할 부분은 Loop문 입니다.
Loop문의 Append lt_table. 전에 break-point를 적용해보고 데이터가 인터널 테이블에 어떻게 추가되는지 봅니다.
첫번쨰 loop

It_table의 id에 It_existing_table의 Is_existing_entry구조체를 통해 id값을 넣고
It_table의 name에 It_existing_table의 Is_existing_entry구조체를 통해 name값을 넣으면
데이터는 it_table의 테이블이아닌 it_table[]에 데이터가 추가 됩니다.
아래처럼 it_table는 비어있습니다.

it_table[]에는 데이터가 추가되어있습니다.

여기서 Append It_table. 구문이 실행되면 아래와같이 it_table 에 데이터가 추가됩니다

반복문을 계속 진행해볼까요? 두번째 Loop중 break-point에 도달하면
It_table와 It_table[]에는 어떤 값이 추가되어있을까요
여기서 궁금한점이 한번의 반복이 끝나면 It_table[]의 값은 초기화 될까요?
정답은 아닙니다.
아래처럼 해당 지점에서 멈춰 lt_table[] 데이터를 봅시다.

lt_table[] 를 보면 ID가 1에서 2로 변경된것을 볼수있는데
NAME 값은 현재 John이라는 것을 알수있습니다.

두번째 Loop가 진행되었을때 각 값은 아래와같이 변경됩니다.
it_table[]의 ID는 2가 되었으며, NAME은 JANE이 되었습니다.

그리고 아래처럼 it_table에 두개의 행이 추가 되었습니다.

지금까지 Loop문을 통해 헤더라인이 있는 인터널 테이블에 데이터를 넣는 방법을 알아봤습니다.
그런데 앞서 말했듯이 현재 s4HANA에서는 헤더라인 사용을 지양하고있습니다.
헤더라인이 없는 인터널 테이블에는 어떤식으로 데이터를 삽입 할 수 있을까요?
헤더라인이 없는 인터널테이블
헤더라인 이 없는 테이블을 선언해줍니다.
TYPES:
BEGIN OF wa_table,
id TYPE i,
name TYPE string,
END OF wa_table.
DATA: lt_table TYPE TABLE OF wa_table.
work area wa_table을 선언하고 헤더라인이 없는 인터널 테이블 It_table을 선언 하였습니다.
헤더라인이 없는 인터널 테이블은 실제로 어떤 구조로 되어있는지 알아 봅시다

앞서 헤더라인인 LT_TABLE[]은 없고 LT_TABLE만 존재하는 것으로 확인됩니다.
그렇다면 해당 테이블에 데이터를 삽입하려면 어떻게해야할까요?
데이터를 삽입 하려면 하나의 스트럭쳐를 선언해주고 데이터를 추가해줘야합니다.
It_existing_table 테이블에 데이터를 삽입하고 it_table (인터널 테이블)에 데이터를 Loop문을 넣는 코드를 통해
헤더라인이 없는 인터널테이블에 데이터가 어떻게 삽입 되는지 알아봅시다.
TYPES:
BEGIN OF wa_table,
id TYPE i,
name TYPE string,
END OF wa_table.
DATA:
" 기존 데이터가 들어있는 테이블 선언
lt_existing_table TYPE TABLE OF wa_table.
" 기존 데이터 삽입 (예시 데이터)
APPEND VALUE #( id = 1 name = 'John' ) TO lt_existing_table.
APPEND VALUE #( id = 2 name = 'Jane' ) TO lt_existing_table.
APPEND VALUE #( id = 3 name = 'Alice' ) TO lt_existing_table.
APPEND VALUE #( id = 4 name = 'Bob' ) TO lt_existing_table.
" 헤더라인이 없는 인터널 테이블 선언
DATA:
lt_table TYPE TABLE OF wa_table.
" 추가용 스트럭쳐 선언
DATA : ls_table_entry LIKE LINE OF lt_table.
" lt_existing_table의 데이터를 lt_table에 추가 (헤더라인 사용 안 함)
LOOP AT lt_existing_table INTO DATA(ls_existing_entry).
" 스트럭쳐에 값을 넣고 테이블에 추가
ls_table_entry-id = ls_existing_entry-id.
ls_table_entry-name = ls_existing_entry-name.
BREAK-POINT.
APPEND ls_table_entry TO lt_table.
ENDLOOP.
앞선 헤더라인이 있는 방식과는 다르게 추가용 스트럭쳐를 선언 하였습니다.
DATA : ls_table_entry LIKE LINE OF lt_table.
이제 IS_tabel_entry에 동일한 방식으로 Loop문으로 데이터를 삽입하여 봅시다.
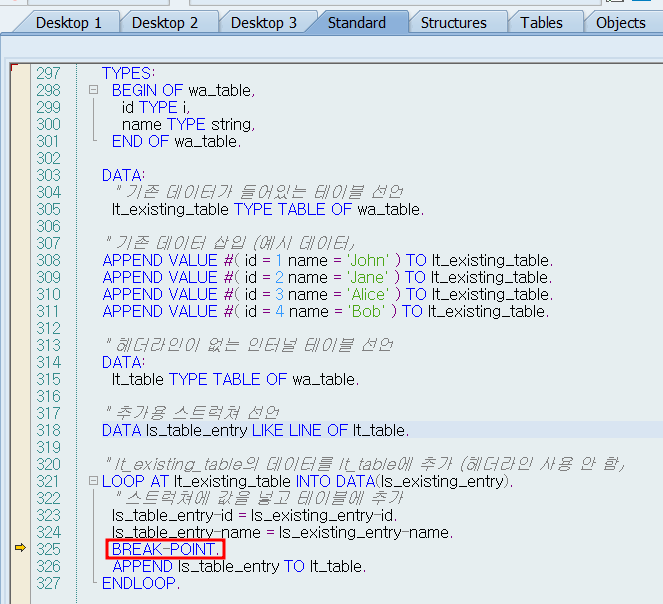
Is_table_entry의 id에 It_existing_table의 Is_existing_entry구조체를 통해 id값을 넣고
Is_table_entry의 name에 It_existing_table의 Is_existing_entry구조체를 통해 name값을 넣으면
구조는 아래와같이 lt_table[] 존재하지 않게 됩니다.
비교해보면 단지 lt_table[]대신에 ls_table_entry을 사용하는것과 동일합니다.

첫번째 브레이크 포인트에서는 아래처럼 It_table는 비어있으며

ls_table_entry에 ID값과 NAME에 추가된것을 확인 할 수 있습니다.

이후 반복되는 내용은 헤더라인이 있는 테이블 Loop문과 동일하여 생각하겠습니다.